
Raft论文翻译
一种更容易理解的共识算法的研究(扩展版)摘要
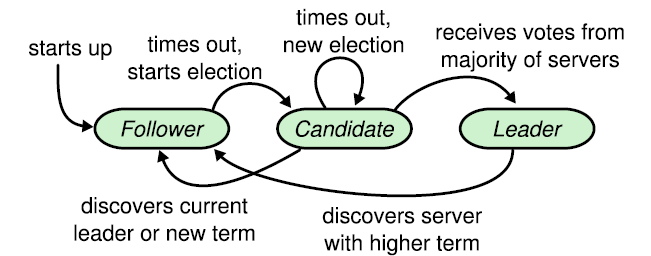
Raft是一种用于管理复制日志的共识算法。它产生和Paxos一样的结果,并且和Paxos一样高效,但是它的结构和Paxos不同;这使得Raft比Paxos更容易理解并且为构建使用系统提供了更好的基础。为了增强可理解性,Raft将共识算法的关键元素分开处理,例如:leader选举,日志复制以及安全性,并且执行更强等级的一致性来减少必须考虑的状态的数量。有研究表明Raft相比于Paxos被学生学习。Raft也包括一些新的机制来改变集群成员,它使用重叠的多数派来保证安全性。
Introduction 共识算法允许一组一起作为一个一致的群体一起工作即便是一些成员出现错误。因此,它在构建一个可靠的大规模的软件系统中发挥着重要作用。在过去的十年里,Paxos在共识算法的讨论中占据主导地位,大部分共识算法的实现都是基于Paxos的,或者收到Paxos的影响,并且Paxos已经变成了教授学生共识算法时的主要工具。
不幸的是,Paxos相当难理解,尽管有许多尝试试图使它更容易接受。此外,他的架构需要复杂的改变才能支持实际的系统。结果就是,系统构建者和 ...
MapReduce论文翻译
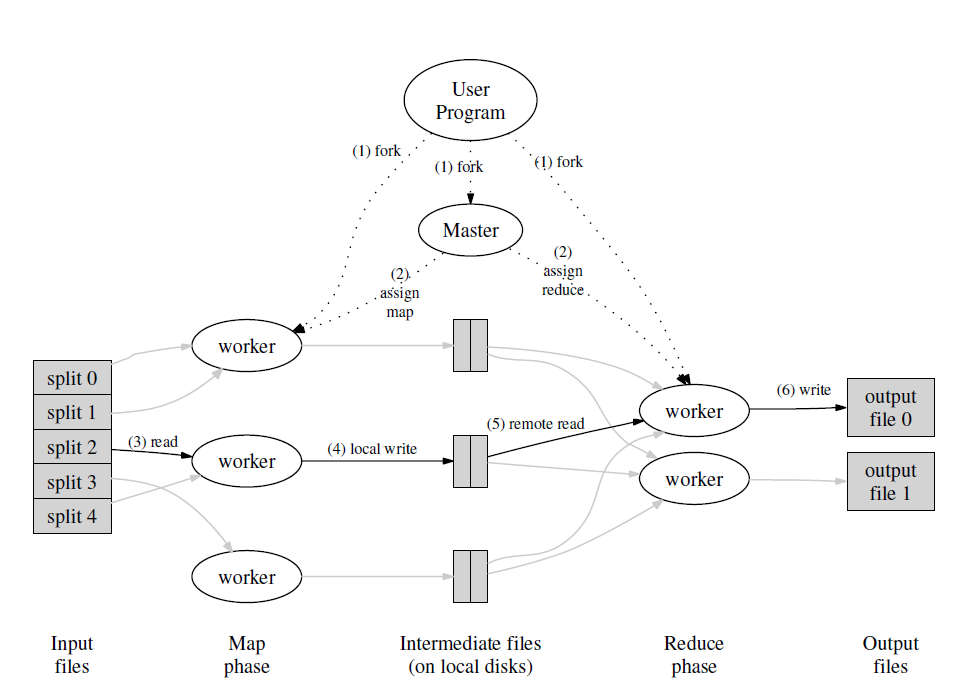
MapReduce: Simplied Data Processing on Large Clusters摘要: MapReduce是一种编程模型和一个相关的实现,用于处理和生成大数据集。用户指定一个map函数,该函数处理一个键值对,然后生成一个一组中间键值对,然后指定一个reduce函数将所有键相同的中间键值对合并。许多真实世界的任务都可以用这种模型来表达,正如论文中展示的那样。
用这种函数式风格编写的程序会自动的并行化,并且在一个集群上执行。运行时系统负责对输入数据进行分区、调度一组机器上的程序的执行、处理机器故障并且管理内部机器之间的通信。这使得没有任何并行和分布式系统经验的编程人员也可以轻松地利用大型分布式系统的资源。
我们的MapReduce实现运行在一大群普通计算机组成的集群上并且高度可伸缩:一个典型的MapReduce计算可以在上千台机器上处理TB级别的数据。编程人员发现这种系统很容易使用:数百个MapReduce程序已经被实现并且每天有上千个MapReduce的任务在谷歌的集群上执行
简介在过去的五年,作者和许多其它在谷歌的人实现了上百个专用的计算来处理大量的原始数据, ...
DDIA第六章:分区
第六章:分区通常情况下,每条数据属于且仅属于一个分区
分区主要是为了可伸缩性,不同的分区可以放在不共享集群中的不同节点上。因此,大数据可以分布在多个磁盘上,并且负载可以分布在多个处理器上
分区与复制分区与复制通常结合使用,使得每个分区的副本存储在多个节点上
一个节点可能存储多个分区。每个节点可能是某些分区的主库,同时也是其他分区的从库
键值数据的分区分区目标是将数据和查询负载均匀分布在各个节点上
如果分区是不公平的,一些分区比其他分区有更多的数据或查询,我们成之为偏斜(shew) 。数据偏斜的存在使分区效率下降很多。不均衡导致的高负载的分区被称为热点(hot spot)
避免热点最简单的方法是将记录随机分配给节点
平均分配数据
缺点是无法知道特定值在哪个节点上,必须并行地查询所有的节点
根据键的范围分区为每个键指定一块连续的键范围。如果知道范围之间的边界,则可以轻松确定哪个分区包含值。如果还知道分区所在的节点,就可以直接向相应的节点发出请求
为了均匀分配数据,分区边界需要依据数据调整。分区边界可以由管理员手动选择,也可以由数据库自动选择
在每个分区中,可以按照一定的顺序保存键。好 ...
DDIA第五章:复制
第二部分:分布式数据处于各种原因,希望将数据库分布到多台机器上:
可伸缩性负载分散到多台机器上
容错/高可用性单台/多台机器出现故障的情况下仍然能继续工作,可以使用多台机器,以提供冗余
延迟
伸缩至更高的载荷第五章:复制可能出于各种各样的原因希望能复制数据
使得数据与用户在地理上接近,从而减少延迟
系统一部分出现故障也能继续工作,从而提高可用性
伸缩可以接收请求的机器数量,从而提高吞吐量
复制的困难之处在于处理复制数据的变更
三种流行的变更复制算法
单领导者(single leader,单主)
多领导者(multi leader, 多主)
无领导者(leaderless, 无主)
复制时需要进行很多权衡
使用同步复制还是异步复制
如何处理失败的副本
······
领导者和追随者存储了数据库拷贝的每个节点称为副本(replica)
存在多个副本时,如何确保所有数据都落在所有副本上?
最常见的方案被称为主/从复制(master/slave) (也称为基于领导者的复制(leader-based replication) 、主动/被动复制(active/passive) ) ...
DDIA第四章
四.编码与演化修改应用程序的功能也可能意味着需要更改其存储的数据:可能需要使用新的字段或记录方式,或者以新的方式展示现有的数据
当数据格式(format)或模式(schema)发生改变时,通常需要对应程序代码进行相应的更改,但在大型应用程序中,代码变更通常不会立即完成:
对于服务端应用程序,可能需要执行滚动升级(rolling upgrade) (也称为阶段发布(staged rollout) ),一次将新版本部署到少数几个节点,检查新版本是否正常运行,然后逐渐部完所有的节点
对于客户端应用程序,升级取决于用户,用户可能相当长一段时间不会去升级软件
新版本的代码以及新旧数据格式可能会在系统中同时共处。系统想要顺利运行,就需要保持双向兼容性:
向后兼容(backward compatibility):新代码可以读取由旧代码写入的数据
向前兼容(forward compatibility):旧的代码可以读取由新的代码写入的数据
编码格式
JSON、XML、Protocol Buffers、Thrift和Avro
Web服务中的数据存储和通信
表属性状态传递(REST)
远程过 ...
DDIA第三章
三. 存储与检索
日志结构的存储引擎
面向页面的存储引擎
驱动数据库的数据结构索引:通过保存一些额外的元数据来作为路标帮助你找到想要的数据
额外的结构,添加与删除索引不影响数据的内容,而只会影响查询的性能
维护额外的结构会产生开销,维护索引减慢写入速度
提高读查询速度
散列索引最简单的索引策略是:保留一个内存中的散列映射,其中每个键都映射到数据文件中的一个字节偏移量,指明了可以找到对应值在数据文件中的位置。写入新键值对时还需要更新散列映射。查找值时使用散列映射来查找数据文件中的偏移量来找到位置。
案例:Bitcask
适合每个键的值经常被更新的情况,例如键是url,值是url被点击的次数,这类工作负载有很多写操作,但没有太多不同的键,将所有键保存在内存中是可行的
如何避免最终用完硬盘空间?
将日志分为特定大小的段,当日志增长到特定尺寸时关闭当前段文件,并开始写入一个新的文件。可以对段进行压缩(conpaction:丢弃重复的键,只保留每个键的最近更新)
压缩可能会使段变得很小,可以在执行压缩的同时将多个段合并在一起。段不可以被修改,所以合并的段被写入一个新的文件。冻结段的 ...

数据库开发
开发成功数据库的要点数据库体系结构的差异
不能把数据库当成“黑盒”使用,因为每个数据库都是非常不同的
并发控制的问题
并发控制保持数据的一致性
锁实现并发控制
不同的数据库实现锁的机制是不一样的
在MySQL和Oracle中读出来是1000
Oracle的多版本控制,读一致性的并发模型
读一致查询:对于一个时间点,查询会产生一致的结果
非阻塞查询:查询不会写入阻塞器,读操作不会回滚
Orcale和MySQL,在修改时会留下快照和时间戳,当读到被修改的数据时读修改前的值,而不会阻塞(是脏数据,但有效)
Oracle实现的锁机制
只有修改才加行级锁
Reader绝对不会对数据加锁
Writer不会阻塞Reader
读写器绝对不会阻塞写入器
对码农的影响
Oracle的无阻塞设计有一个副作用,就是如果确实想确保一次最多只有一个用户访问一行数据,就得开发人员自己做一些工作
数据库是不同的,二者之间可能存在一些剧本差别,可能还有一些细微的差别
性能调优(目前情况下性能优化至最优)
根据当前CPU能力,可用内存,I/O系统等资源情况来设置相应的参数
通过索引,物理结构,S ...
DDIA第二章
二. 数据模型与查询语言多数应用程序使用层层叠加的数据模型构建,对于每层数据模型的关键问题是:它是如何用低一层的数据模型来表示的
关系模型与文档模型数据被组织成关系,其中每个关系是元组(行)的无序集合,关系型模型致力于将数据库内部的数据表示的细节隐藏在更简洁的接口之后
NoSQL背后的几个驱动因素
需要比关系型数据库更好的可伸缩性,包括非常大的数据集或非常高的写入吞吐量
相比商业数据库,免费和开源软件更受偏爱
关系模型不能很好地支持一些特殊的查询操作
渴望一种,不受限于关系模型的,根据多动态性与表现力的数据模型
混合持久化:不同应用程序有不同的需求,一个用例的最佳技术选择可能不同于另一个用例的最佳技术选择,关系数据库与各种非关系数据库可能会一起使用
对象关系不匹配
大多数应用程序都使用面向对象的编程语言来开发,如果数据存储在关系表中,那么需要一个笨拙的转换层,处于对象和表、行、列的数据库模型之间,这样模型之间的不连贯有时被称为阻抗不匹配
ORM可以减少这个转换层所需的样板代码的数量,但是不嫩个完全隐藏这两个模型之间的差异
一对多关系
JSON比多表的关系模式具有更好的 ...
JVM
内存结构程序计数器
如果线程正在执行一个Java方法,则这个计数器记录的正在执行虚拟机字节码指令的地址;如果正在执行的是Native方法,则这个计数器的值为空(Undefined)
线程私有
不会存在内存溢出
Java虚拟机栈
每个线程运行时所需要的内存,称为虚拟机栈
每个栈由多个栈帧组成,对应着每次方法调用时所占用的内存
每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法
方法内局部变量是否安全:
如果方法内局部变量没有逃离方法的作用范围,它是线程安全的
如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全
本地方法栈
堆
通过new创建的对象会使用堆内存
线程共享,需要考虑线程安全
有垃圾回收机制
jps
查看当前系统中有哪些Java进程
jmap
查看堆内存使用情况jmap -heap id
jconsole
图形界面
jvisualvm
方法区
线程共享
存储和类相关的信息
1.8前会导致永久代内存溢出,后会导致元空间内存溢出
常量池
常量池就是一张表,虚拟机根据这张常量表找到要执行的类名、方法名、类 ...

软件分析
01-Introduction为什么需要静态分析
程序可靠性:例如空指针引用,内存泄露
程序安全性:私有信息泄露,注入攻击等等
编译优化:Dead code elimination, code motion
程序理解:IDE中哪些方法被调用,调用了哪些方法,类型检测
Sound
多报,误报,包含Truth
Complete
少报,漏报,一定是Truth
useful static analysis
Compromise soundness (false negatives)
Compromise completeness (false positives)
大部分静态分析追求sound,不完全准确的静态分析
Soundness的必要性Soundness is critical to a collection of important (static-analysis) applications such as compiler optimization and program verification
静态分析例子
采用2的结果
静态分析确保soundness,在 ...