
NoSQL
关系型数据库的价值
获取持久化数据
- 持久储存大量数据
- 在大多数的计算机架构中,有两个存储区域
- 速度快但数据易丢失的“主存储器”
- 空间有限
- 易挥发
- 存储量大但速度较慢的“后备存储器”
- 文件系统
- 数据库
- 速度快但数据易丢失的“主存储器”
并发
多个用户会一起访问同一份数据体,并且可能要修改这份数据。(大多数情况下,他们都在不同数据区域内各自操作,但是,偶尔也会同时操作一小块数据)
关系型数据库提供了 “事务”机制来控制对其数据的访问,以便处理此问题。
事务在处理错误时也有用。通过事务更改数据时,如果在处理变更的过程中出错了,那么就可以回滚(roll back)这一事务,以保证数据不受破坏。
集成
企业级应用程序居于一个丰富的生态系统中,它需要与其他应用程序协同工作。不同的应用程序经常要使用同一份数据,而且某个应用程序更新完数据之后,必须让其他应用程序知道这份数据已经改变了。
常用的办法是使用共享数据库集成(shared database integration) ,多个应用程序都将数据保存在同一个数据库中。这样一来,所有应用程序很容易就能使用彼此的数据了。
与多用户访问单一应用程序时一样,数据库的并发控制机制也可以应对多个应用程序。
近乎标准的模型
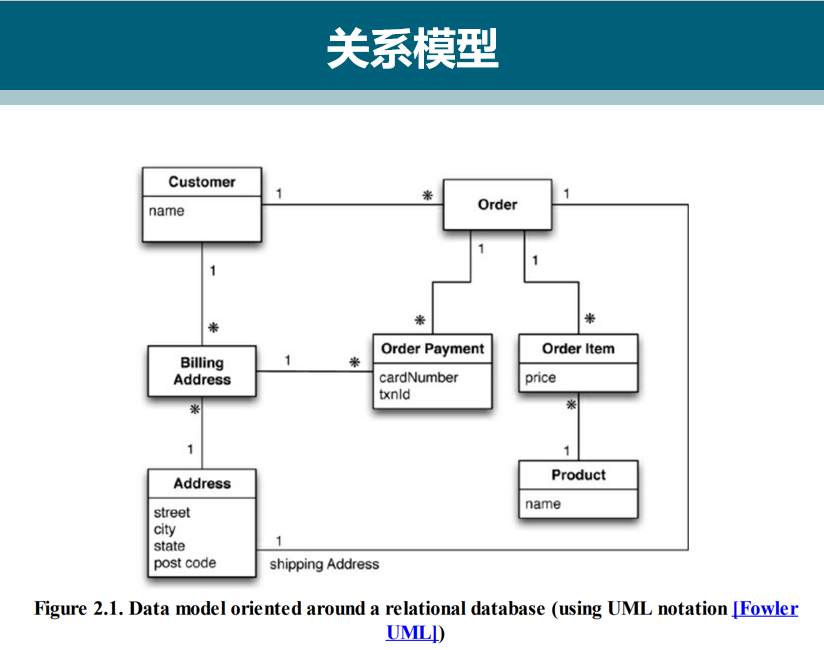
关系型数据库以近乎标准的方式提供了数据模型。
尽管各种关系型数据库之间仍有差异,但其核心机制相同
- 不同厂商的SQL方言相似
- “事务” 的操作方式也几乎一样
由来
阻抗失谐
基于关系代数(relational algebra),关系模型把数据组织成 “关系”(relation)和“元组”(tuple)。
- 元组是由“键值对”(name-value pair)构成的集合
- 而关系则是元组的集合。
- SQL操作所使用及返回的数据都是“关系”
- 元组不能包含“嵌套记录”(nested record)或“列表”(list) 等任何结构
而内存中的数据结构则无此限制,它可以使用的数据组织形式比“关系”更丰富。
关系模型和内存中的数据结构之间存在差异。这种现象通常称为“阻抗失谐”。
- 如果在内存中使用了较为丰富的数据结构,那么要把它保存到磁盘之前,必须先将其转换成“关系形式。于是就发生了“阻抗失谐”:需要在两种不同的表示形式之间转译
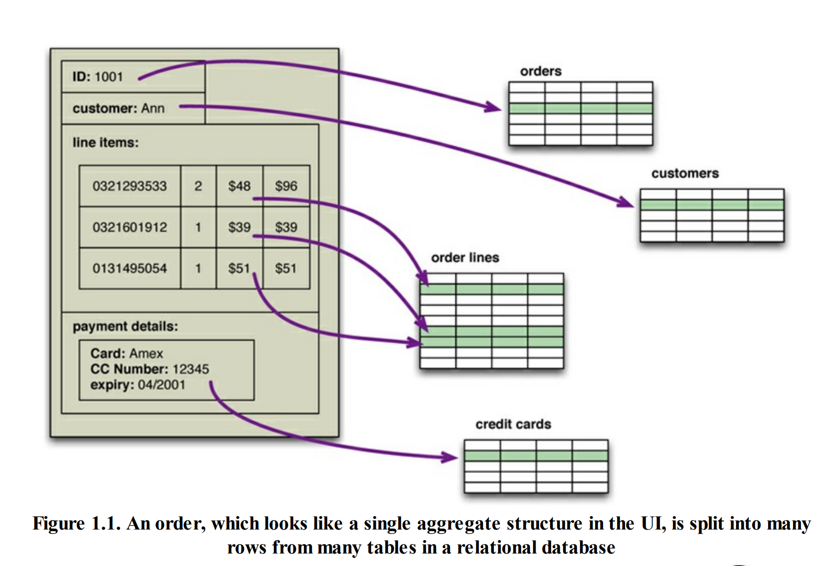
解决办法
- 面向对象数据库
- 对象-关系映射框架:通过映射模式表达转换
存在查询性能问题和集成问题
集成数据库

应用程序数据库

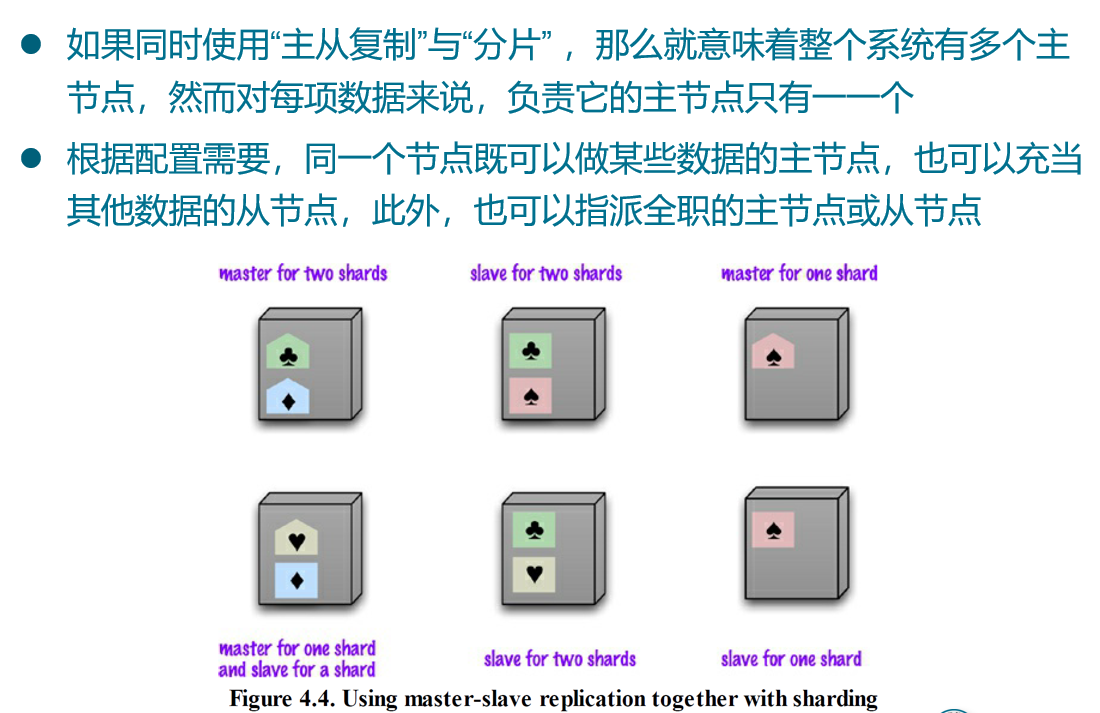
集群问题

$NoSQL$

聚合
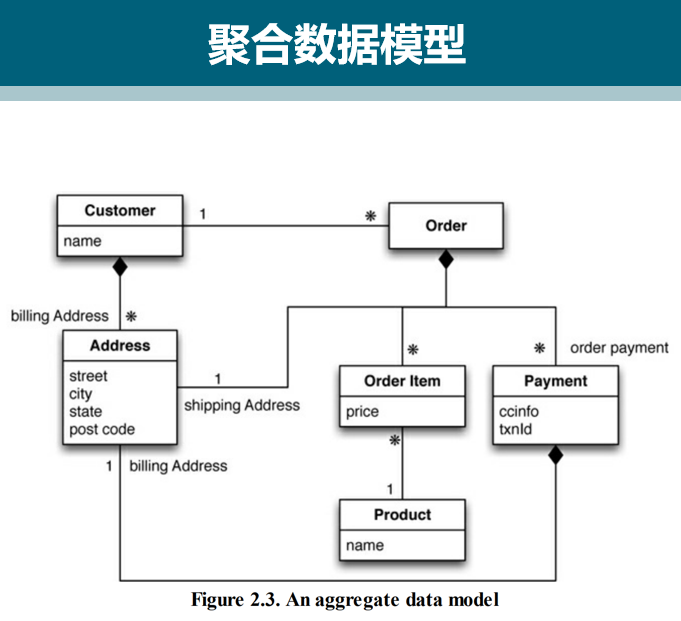
把一组相互关联的对象视为一个整体单元来操作,而这个单元就叫聚合(aggregate)。
通过原子操作(atomic operation)更新聚合的值(含一致性管理)
以聚合为单位与数据存储通信
在集群中操作数据库时,用聚合为单位来复制和分片
由于程序员经常通过聚合结构来操作数据,故而采用聚合也能让其工作更为轻松。面向聚合操作数据时所用的单元,其结构比元组集合复杂得多
“键值数据库”、“文档数据库”、“列族数据库”

聚合无知
关系型数据库的数据模型中,没有“聚合”这一概念,因此我们称之为“聚合无知”(aggregate- ignorant)。
- “图数据库”也是聚合无知的。
聚合反应数据操作的边界,很难在共享数据的多个场景中“正确” 划分,对某些数据交互有用的聚合结构,可能会阻碍另一些数据交互
在客户下单并核查订单,以及零售商处理订单时,将订单视为一个聚合结构就比较合适。
如零售商要分析过去几个月的产品销售情况,那么把订单做成一个聚合结构反而麻烦了。要取得商品销售记录,就必须深挖数据库中的每一个聚合。
若是采用“聚合无知模型”,那么很容易就能以不同方式来查看数据
在操作数据时,如果没有一种占主导地位的结构,那么选用此模型效果会更好。
聚合之间的关系
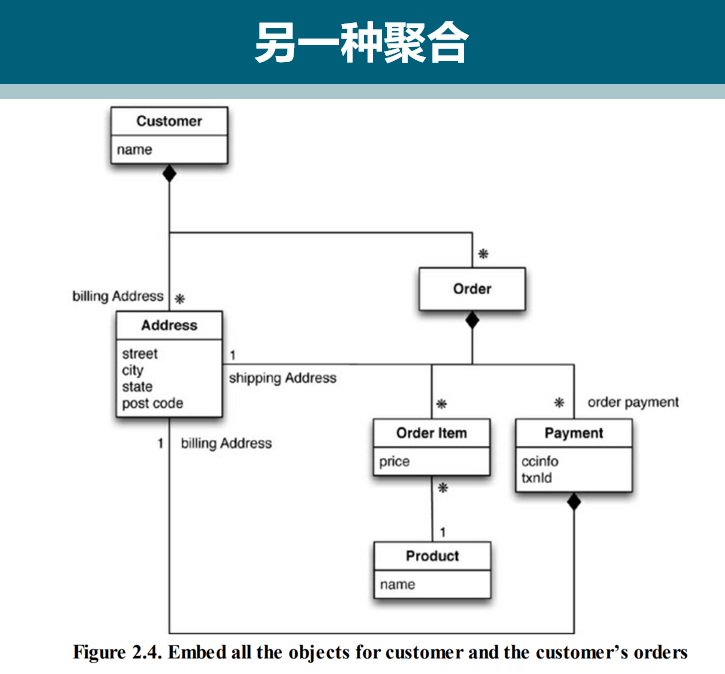
例如:把订单和客户放在两个聚合中,但是想在它们之间设定某种关系,以便能根据订单查出客户数据。
要提供这种关联,最简单的办法就是把客户ID嵌入订单的聚合数据中。在应用层级提供关联。
在数据库层级提供聚合之间关系的表达机制
操作多个有关联的聚合,由应用保证其正确性
- 面向聚合数据库获取数据时以聚合为单元,只能保证单一聚合内部内容的原子性。
聚合、集群和事务处理
在集群上运行时,需要把采集数据时所需的节点数降至最小
- 如果在数据库中明确包含聚合结构,那么它就可以根据这一重要信息,知道哪些数据需要一起操作了,而且这些数据应该放在同一个节点中
通常情况下,面向聚合的数据库不支持跨越多个聚合的ACID事务。它每次只能在一个聚合结构上执行原子操作。
如果想以原子方式操作多个聚合,那么就必须自己组织应用程序的代码
在实际应用中,大多数原子操作都可以局限于某个聚合结构内部,而且,在将数据划分为聚合时,这也是要考虑的因素之一
主要的$NoSQL$数据模型
键值数据模型与文档数据模型
这两类数据库都包含大量聚合,每个聚合中都有一个获取数据所用的键或ID。
两种模型的区别是:
- 键值数据库的聚合不透明,只包含一些没有太多意义的大块信息
- 聚合中可以存储任意数据。数据库可能会限制聚合的总大小,但除此之外,其他方面都很随意
- 在键值数据库中,要访问聚合内容,只能通过键来查找
- 在文档数据库的聚合中,可以看到其结构。
- 限制其中存放的内容,它定义了其允许的结构与数据类型
- 能够更加灵活地访问数据。通过用聚合中的字段查询,可以只获取一部分聚合,而不用获取全部内容
- 可以按照聚合内容创建索引
列族存储
大部分数据库都以行为单元存储数据。然而,有些情况下写入操作执行得很少,但是经常需要一次读取若干行中的很多列。此时,列存储数据库将所有行的某一组作为基本存储单元
列族数据库将列组织为列族。每一列都必须是某个列族的一部分,而且访问数据的单元也得是列
- 某个列族中的数据经常需要一起访问
列族模型将其视为两级聚合结构
- 与“键值存储”相同,第一个键通常代表行标识符,可以用它来获取想要的聚合
- 列族结构与“键值存储”的区别在于,其“行聚合”本身又是一个映射,其中包含一些更为详细的值。这些“二级值”就叫做“列”。与整体访问某行数据一样,我们可以操作特定的列
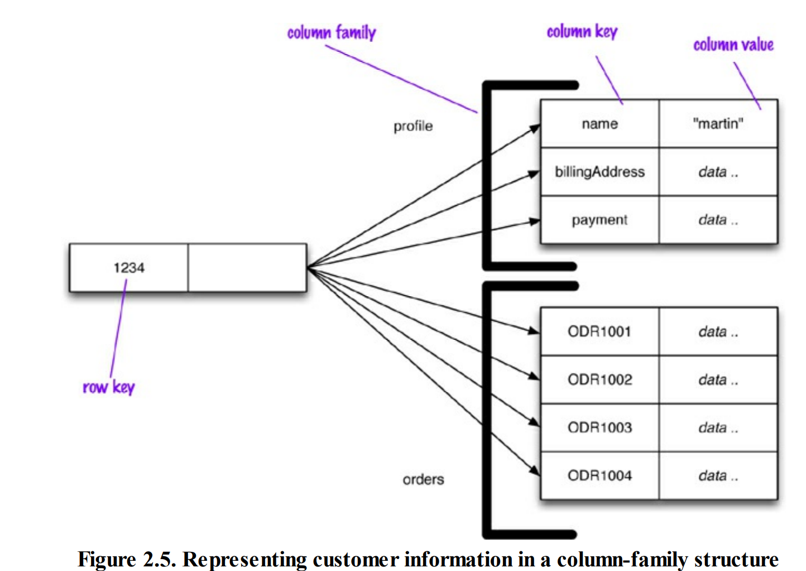
两种数据组织方式
- 面向行:每一行都是一个聚合,例如ID为1234的顾客就是一个聚合,该聚合内部存有一些包含有用数据块(客户信息、订单纪录)的列族
- 面向列:每个列族都定义了一种记录类型(例如客户信息),其中每行都表示一条记录。数据库中的大“行”理解为列族中每一个短行记录的串接
面向聚合的数据模型
共同点
都使用聚合这一概念,而且聚合中都有一个可以查找其内容的索引键。
在集群上运行时,聚合是中心环节,因为数据库必须保证将聚合内的数据存放在同一个节点上。
聚合是“更新”操作的最小数据单位(atomic unit),对事务控制来说,以聚合为操作单元
差别
键值数据模型将聚合看作不透明的整体,只能根据键来查出整个聚合,而不能仅仅查询或获取其中的一部分
文档模型的聚合对数据库透明,于是就可以只查询并获取其中一部分数据了,不过,由于文档没有模式,因此在想优化存储并获取聚合中的部分内容时,数据库不太好调整文档结构
列族模型把聚合分为列族,让数据库将其视为行聚合内的一个数据单元。此类聚合的结构有某种限制,但是数据库可利用此种结构的优点来提高其易访问性。
图数据库
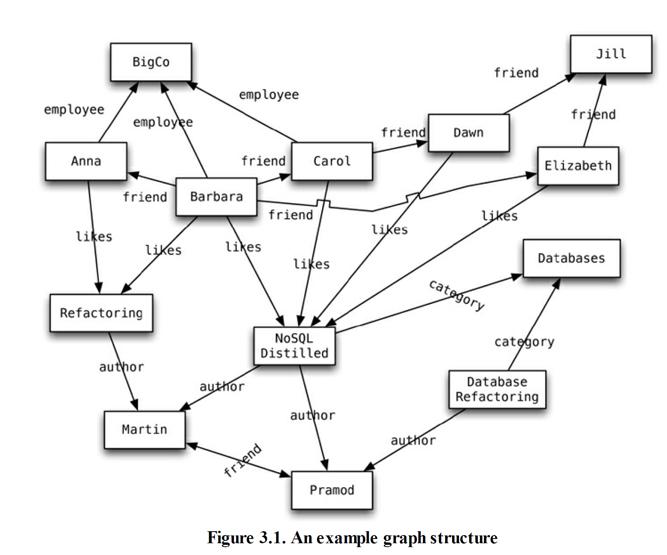
图数据库的基本数据模型:由边(或称“弧”,arc)连接而成的若干节点。
可以用专门为“图”而设计的查询操作来搜寻图数据库的网络了
- 指定节点,通过边进行查询
关系型数据可以通过“外键”实现,查询中的多次连接,效率较差
无模式
$NoSQL$数据库无模式:
- “键值数据库”可以把任何数据存放在一个“键”的名下
- “文档数据库”对所存储的文档结构没有限制
- 在列族数据库中,任意列里面都可以随意存放数据
- 图数据库中可以新增边,也可以随意向节点和边中添加属性
格式不一致的数据
每条记录都拥有不同字段集(set of field)
关系型数据库中,“模式”会将表内每一行的数据类型强行统一,若不同行所存放的数据类型不同,那这么做就很别扭。
要么得分别用很多列来存放这些数据,而且把用不到的字段值填成null(这就成了”稀疏表”,sparse table),
要么就要使用类似custom column 4这样没有意义的列类型。
无模式表则没有这么麻烦,每条记录只要包含其需要的数据即可,不用再担心上面的问题了。
无模式的问题
存在“隐含模式”。在编写数据操作代码时,对数据结构所做的一系列假设
应用与数据的耦合问题
无法在数据库层级优化和验证数据
在集成数据库中,很难解决
使用应用程序数据库,并使用$Web Services、SOA$等完成集成
在聚合中为不同应用程序明确划分出不同区域
- 在文档数据库中,可以把文档分成不同的区段(section)
- 在列族数据库,可以把不同的列族分给不同的应用程序
分布式数据库
数据分布有两条路径,既可以在两者中选一个来用,也可以同时使用它们
- 分片:将不同数据存放在不同节点中
- 复制:将同一份数据拷贝至多个节点
- 主从式和对等式
分片
一般来说,数据库的繁忙体现在:不同用户需要访问数据集中的不同部分,在这种情况下,把数据的各个部分存放于不同的服务器中,一次实现横向扩展,这种技术就叫分片
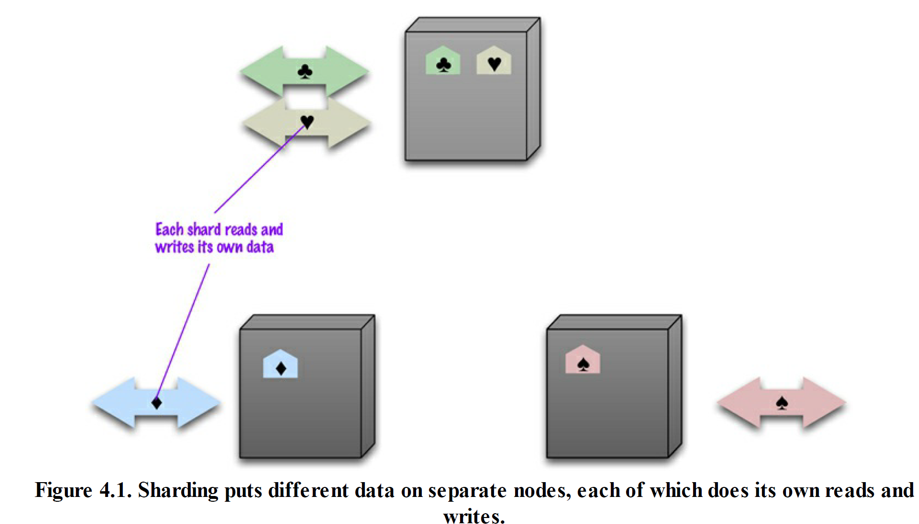
在理想情况下,不同的服务器节点会服务于不同的用户。每位用户只需与一台服务器通信,并且很快就能获得服务器的响应。网络负载相当均衡地分布于各台服务器上。
为达成目标,必须保证需要同时访问的那些数据都存放在同一节点上,而且节点必须排布好这些数据块,使访问速度最优。
若使用面向聚合的数据库,可以把聚合作为分布数据的单元。
在节点的数据排布问题上,有若干个与性能改善相关的因素。
- 地理因素
- 负载均衡
- 聚合有序放置
采用应用程序的逻辑实现分片
编程模型复杂化,因为应用程序的代码必须负责把查询操作分布到多个分片上
若想重新调整分片,那么既要修改程序代码,又要迁移数据
采用NoSQL数据库提供的“自动分片”( auto-sharding)功能
让数据库自己负责把数据分布到各分片
并且将数据访问请求引导至适当的分片上
分片可以同时提升读取与写入效率
- 使用“复制”技术,尤其是带缓存的复制,可以极大地改善读取性能,但对于写操作帮助不大
分片对改善数据库的“故障恢复能力”帮助并不大。尽管数据分布在不同的节点上,但是和“单一服务器”方案一样,只要某节点出错,那么该分片上的数据就无法访问了
在发生故障时,只有访问此数据的那些用户才会受影响,而其余用户则能正常访问
由于多节点问题,从实际效果出发,分片技术可能会降低数据库的错误恢复能力
复制
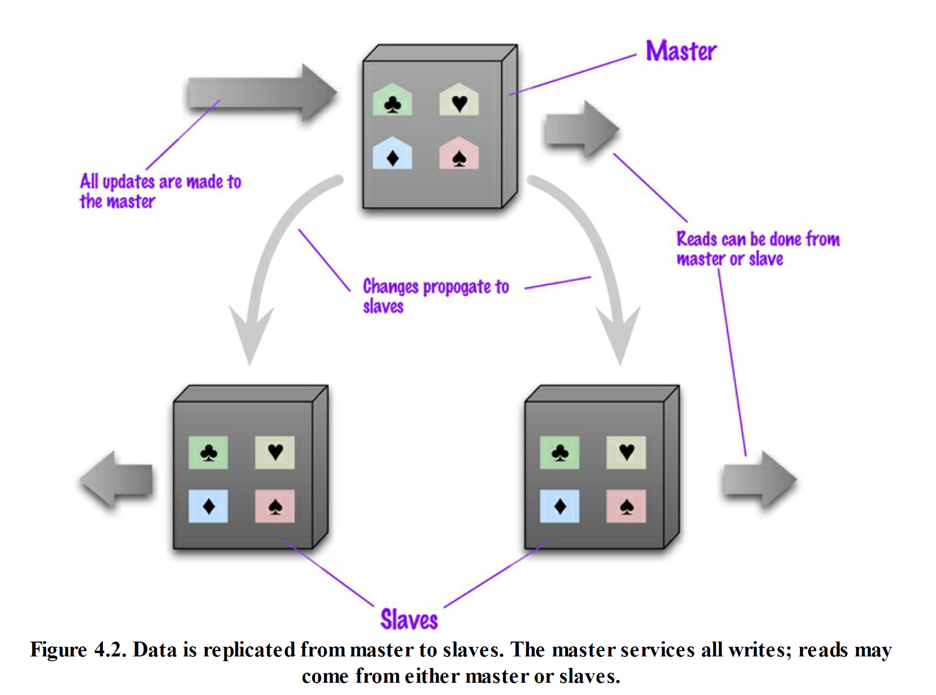

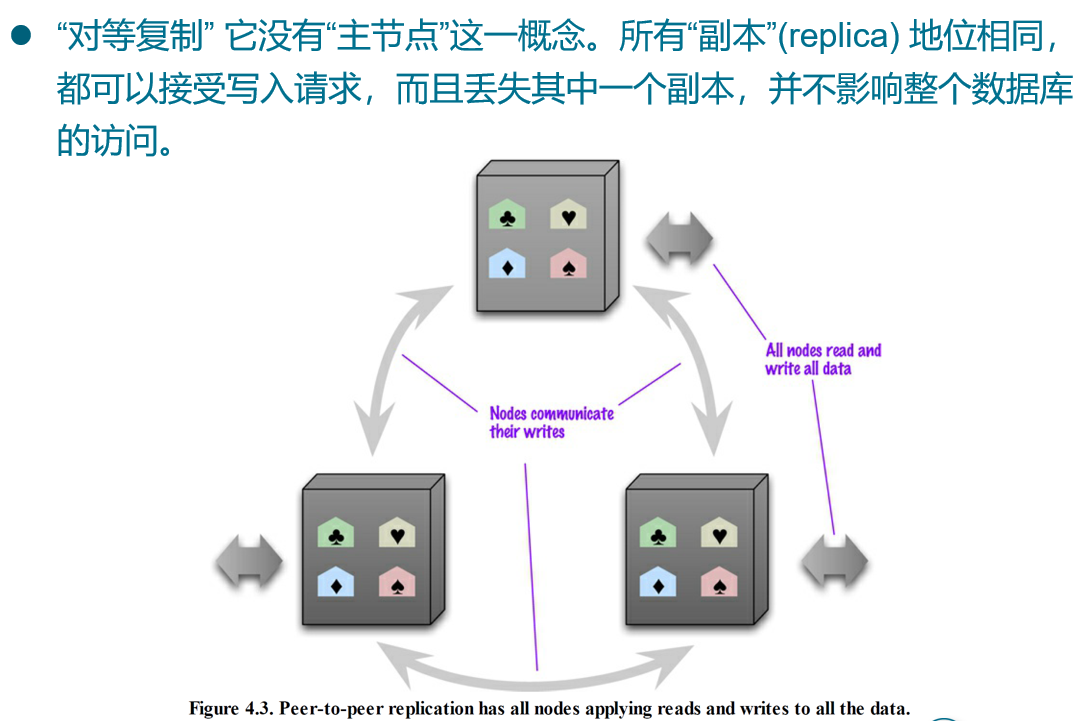

分布式模型中的一致性
当两个客户端试图同时修改一份数据时,会发生“写入冲突”。而当某客户端在另一客户端执行写入操作的过程中读取数据时,则会发生“读写冲突”
悲观方式以锁定数据纪律来避免冲突:写入锁
乐观方式则在事后检测冲突并将其恢复
- “条件更新”,任意客户在执行更新操作之前,都要先测试数据的当前值和上一次读入的值是否相同
- 保存冲突数据。用户自行合并或自动合并
“图数据库”常常和关系型数据库一样,也支持ACID事务
面向聚合的数据库通常支持“原子更新”,但仅限于单一聚合内部,“一致性”可以在某个聚合内部保持,但在各聚合之间则不行,在执行影响多个聚合的更新操作时,会留下一段时间空挡,让客户端有可能在此刻读出逻辑不一致的数据,存在不一致风险的时间长度就叫“不一致窗口”。
复制一致性:
要求从不同副本中欧冠读取同一个数据项时,所得到的值相同
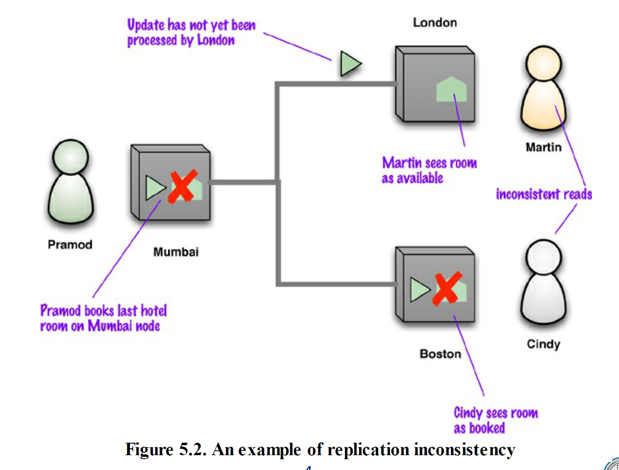
在分布式系统中,如果某些节点收到了更新数据,而另外一些节点却尚未收到,那么这种情况就视为“读写冲突”。
若写入操作已经传播至所有节点,则此刻的数据库就具备“最终一致性”( eventually consistent)
复制不一致性带来的“不一致窗口”,在考虑网络环境后,会比单一节点导致的“不一致窗口”长的多
- 不一致性窗口对应用的影响不同


