
数据库开发
开发成功数据库的要点
数据库体系结构的差异
不能把数据库当成“黑盒”使用,因为每个数据库都是非常不同的
并发控制的问题
- 并发控制保持数据的一致性
- 锁实现并发控制
- 不同的数据库实现锁的机制是不一样的
在MySQL和Oracle中读出来是1000
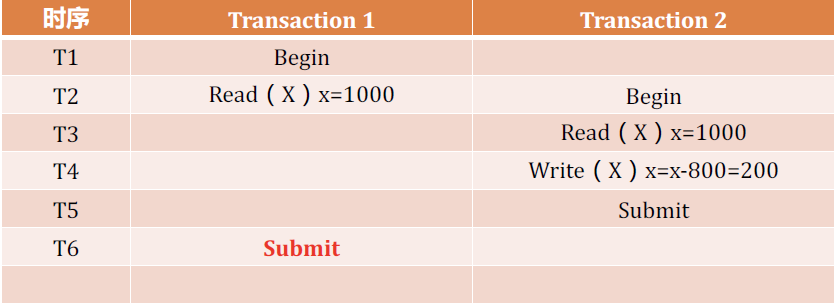
Oracle的多版本控制,读一致性的并发模型
- 读一致查询:对于一个时间点,查询会产生一致的结果
- 非阻塞查询:查询不会写入阻塞器,读操作不会回滚
Orcale和MySQL,在修改时会留下快照和时间戳,当读到被修改的数据时读修改前的值,而不会阻塞(是脏数据,但有效)
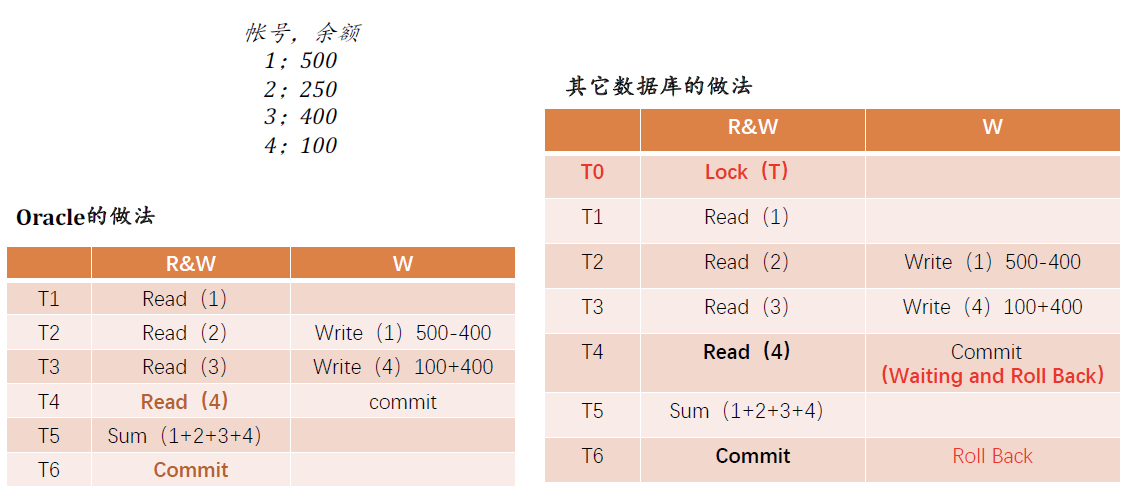
Oracle实现的锁机制
- 只有修改才加行级锁
- Reader绝对不会对数据加锁
- Writer不会阻塞Reader
- 读写器绝对不会阻塞写入器
对码农的影响
- Oracle的无阻塞设计有一个副作用,就是如果确实想确保一次最多只有一个用户访问一行数据,就得开发人员自己做一些工作
数据库是不同的,二者之间可能存在一些剧本差别,可能还有一些细微的差别
性能调优(目前情况下性能优化至最优)
- 根据当前CPU能力,可用内存,I/O系统等资源情况来设置相应的参数
- 通过索引,物理结构,SQL的优化,具体提高某一个查询的性能
性能拙劣的罪魁祸首是错误的设计
- 提高整体性能
- 技巧决定系统性能的下限
- 设计决定系统性能的上限
性能优化要考虑成本
- 性能指标都是有成本的、安全和优化中寻找平衡
- 性能指标以吞吐量为核心(每秒处理多少事务)
- 性能指标要考虑整体性
- 优化手段本身就有很大的风险
- 任何一个技术可以解决一个问题,但存在另一个问题的风险
- 对于带来的风险,控制在可接受范围内才是有成果的
- 性能优化技术,使得性能变好,维持和变差是等概率事件
整体层面的性能优化考虑
问题一:cpu负载高,io负载低
问题二:io负载高,cpu负载低
- 大量小的io执行写操作
- 自动提交,产生大量小io
- 大量大的io执行写操作
- SQL的问题
- IO/PS磁盘限定一个每秒最大的IO次数
问题三:io和cpu负载都高
- 硬件不够用了
- SQL存在问题(循环中有SQL,SQL不断被执行,SQL本身也是一个循环)
SQL优化方向
- 索引
- 执行计划
- SQL语句优化
- 物理分库分表
- 数据库表结构
- 整体结构设计
数据库的物理实现
分区、分表、分库
就是把一张表的数据分成N个区块,在逻辑上看最终还是一张表,但底层是由N个物理区块组成的
分区的实现方式
- 哈希分区
- 范围分区
- 列表分区
分区的一些缺点
- 如果sql不走分区键,很容易造成全表锁
- 在分区中实现关联查询,就是一个灾难
- 分区表,隐藏复杂,使得工程师不可控
- DBA给OP埋坑,容易大打出手,造成同时矛盾
分表
把一张表按一定的规则分解成N个具有独立存储空间的实体表。系统读写时需要根据定义好的规则得到对应的字表名然后操作它
解决的问题
- 分表后单表的并发能力提高,磁盘IO性能也提高,写操作效率提高了
- 数据分布在不同文件,磁盘IO性能提高
- 读写锁影响的数据量变小
- 插入数据库需要重新建立索引的数据减少
分区分库分表
IO瓶颈
- 热点数据太多,数据缓存不够,每次查询产生大量IO——分库、垂直分表
- 网络IO瓶颈,请求数据太多,带宽不够,连接数过多——分库
CPU瓶颈
- SQL问题——SQL优化,构建索引
- 单表数据过大,扫描行太多——水平分表
全局ID生成策略
自动增长列
UUID 简单,全球唯一但是存储和传输空间大,无序,性能欠佳
COMB(组合)
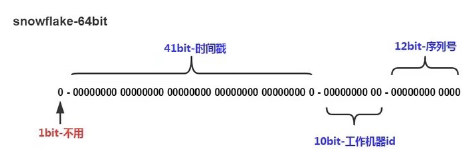
Snowflake(雪花算法)
long值,特征是各个节点无需协调,按时间大致有序,且整个集群各个节点不重复
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 划水摸鱼!
